
自宅サーバーで動くプライベートAIアシスタントを構築してみた。OpenClawを使ってDiscord連携までこぎつけるのに丸2日かかったけど、その過程で踏んだ罠は全部記録しておく。これから挑戦する人の参考になればと思う。
結論から言うと #
最終的に動いた構成
- N150サーバー(NucBox G9 / Ubuntu Server): 24時間稼働の司令塔、OpenClawをDockerで運用
- Mac mini M4 Pro 24GB: Ollama + Qwen 3.5 9B、必要な時だけWake on LANで起動
- Tailscale: ポート開放なし、外出先から安全にアクセス
- Discord Bot: スマホからメンションで会話、30秒以内に応答
クラウドのChatGPTやClaudeに頼らず、家族の写真整理や仕事のメモを完全プライベートで処理できる環境。月額換算で数万円分のサービスが手元のハードで動く。
全体構成図 #
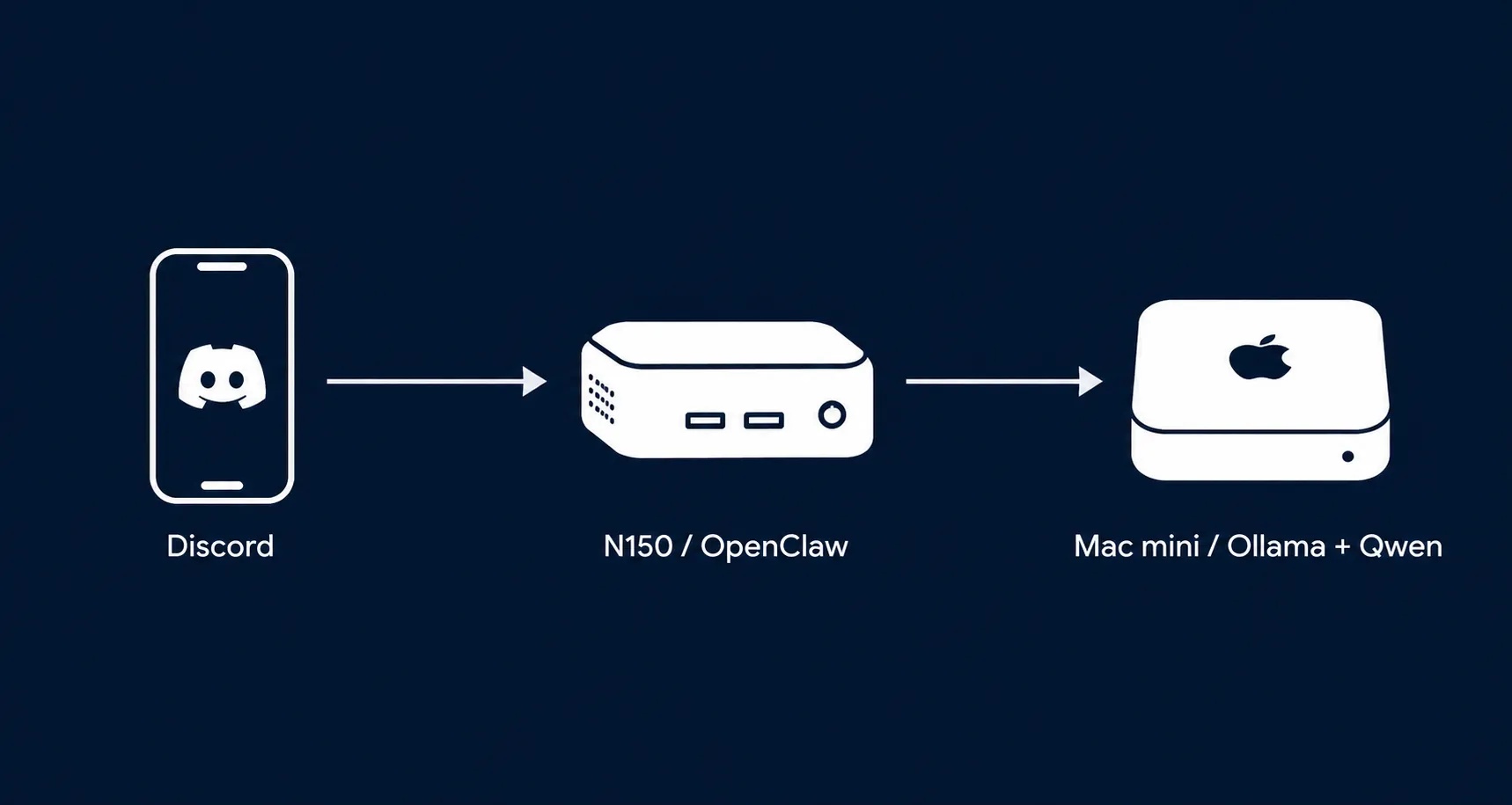
[スマホ/PC] ─Tailscale─→ [N150サーバー: OpenClaw Gateway]
↓
[Mac mini: Ollama + Qwen]メッセージの流れ: Discord → OpenClaw(N150) → Ollama(Mac mini) → Qwen推論 → Discord返信
なぜこの構成にしたか #
最初は「N150サーバー1台でLLM動かせないか」と考えた。が、N150(Intel N150、TDP 6W)は省電力CPU、内蔵GPU、RAM 12GB。ローカルLLMを快適に動かすには非力すぎる。CPU推論だと毎秒1〜2トークン、まともに使えない。
一方、手元にあったMac mini M4 ProはユニファイドメモリでLLM推論が得意。ただ「常時電源は嫌」という気持ちがあった。
そこで思いついたのが役割分担:
- N150 = 常時稼働の「司令塔」(OpenClaw、ファイル共有、Time Machine)
- Mac mini = 必要時のみ起動の「頭脳」(Ollama)
これがハマった。N150でDiscordからのリクエストを受けたら、Wake on LANでMac miniを起こし、Ollamaに推論を投げ、結果を返す。個人運用のローカルLLMとして、省電力と性能を両立できるアーキテクチャだ。
GMKtec NucBox G9 ミニPC(Intel N150)
Apple Mac mini (M4 Pro / 24GBメモリ)
構築ステップ全体 #
- Tailscaleでネットワーク構築
- Mac mini側にWake on LAN設定
- N150 → Mac mini SSH鍵認証
- Mac miniにOllamaインストール
- Qwenモデルをpull
- N150にDocker + OpenClawインストール
- OpenClawをOllamaに接続
- OpenClawをDiscordに接続
- 最大の罠を解決
順に書いていく。
Step 1: Tailscaleでネットワーク構築 #
これは正解中の正解だった。ポート開放は絶対にしない。Tailscaleで仮想的に閉じたネットワークを作れば、外出先からも安全に自宅サーバーにアクセスできる。
ポイント:
- サブネットルーティングを有効化 → N150経由でLAN内の他デバイス(Mac miniなど)にもアクセス可能
- MagicDNSを有効化 → IPアドレスではなくホスト名で接続できる(
nucbox、macminiなど)
出先でも隙間時間にBotと会話する想定なので、外出先からのアクセスは必須要件だった。
Step 2: Mac miniのWake on LAN設定 #
「常時電源は嫌、でも必要な時だけ起こしたい」を実現する仕組み。
Mac mini側:
- 有線LAN接続(Wi-FiではWoLは実質動かない)
- システム設定 → エネルギー → 「ネットワークアクセスによるスリープ解除」をオン
- MACアドレスをメモ
Cat6A LANケーブル(1〜2m)
MacBook等でLAN端子がない場合はアダプターが必要。
USB-C ギガビットLANアダプター
N150側でスクリプト作成:
#!/bin/bash
MAC_ADDRESS="XX:XX:XX:XX:XX:XX"
BROADCAST="192.168.1.255"
TARGET_IP="192.168.1.13"
echo "Mac mini に起床要請を送信..."
wakeonlan -i $BROADCAST $MAC_ADDRESS
# 起動確認(pingで最大60秒待つ)
for i in $(seq 1 60); do
if ping -c 1 -W 1 $TARGET_IP > /dev/null 2>&1; then
echo "Mac mini 起動完了(${i}秒)"
exit 0
fi
sleep 1
done
echo "タイムアウト"学び: M4 Proはパワーナップが効いていて、スリープ中もネットワーク応答する。pingは通り続けるが、それは「Mac本体が起きている」サインではない。実際に推論リクエストが来るとフル稼働に切り替わる仕組み。
Mac miniの再スリープ自動化(補足) #
WoLで起こした後、しばらくリクエストがなければ自動でスリープに戻す仕組みも作っておくと電力効率が上がる。N150側からSSH経由でスリープコマンドを送る方法がシンプルだ。
# 一定時間アイドル後にMac miniをスリープ
ssh [email protected] "osascript -e 'tell application \"System Events\" to sleep'"Cronやsystemdタイマーで「最後のOllama利用から30分後にスリープ」のような自動化をすれば、完全なエコシステムが完成する。
Step 3: SSH鍵認証 #
外出先からN150経由でMac miniを操作するために、パスワードレスのSSH接続を設定。
# N150側
ssh-keygen -t ed25519 -C "n150 to macmini"
ssh-copy-id [email protected]シンプルだが必須。Mac mini側で「リモートログイン」を有効化しておくのを忘れずに(システム設定 → 一般 → 共有)。
Step 4: Mac miniにOllamaインストール ─ 最初の罠 #
ここで予想外の沼にハマった。
ollama --version を叩くと zsh: illegal hardware instruction というエラー。
原因を追ったところ、Mac mini M4 ProにIntel版のbrewがインストールされていて、そこから入ったOllamaもx86_64バイナリだった。M2 MacBookから移行アシスタントで持ってきた .zshrc に以下のエイリアスが残っていたのだ:
alias brew="arch -arch x86_64 /usr/local/bin/brew"これがあると、Apple Silicon用のbrewを入れようとしても強制的にIntel版brewが呼ばれてしまう。
解決手順:
.zshrcから該当エイリアスを削除- Intel版brewを完全アンインストール
- Apple Silicon版brewを
/opt/homebrewにクリーンインストール - Apple Silicon版Ollamaを
brew install ollama
教訓: Mac間の移行後は .zshrc の中身を確認すること。which brew で /opt/homebrew/bin/brew になっているかチェック。
Step 5: Ollamaの外部公開設定 #
デフォルトではOllamaは 127.0.0.1:11434 でしかLISTENしない。N150からアクセスするには全インターフェースで待ち受けさせる必要がある。
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
brew services restart ollama
# 確認
lsof -i :11434
# → *:11434 (LISTEN) になっていればOKこれで curl http://192.168.1.13:11434/api/tags がN150から通るようになる。
Step 6: Qwenモデルのpull #
ここで「最強モデルを選びたい!」と思って Qwen 3.6 27B を選んだのが第2の罠(後述)。
最終的に落ち着いたのは Qwen 3.5 9B(約6.6GB)。
ollama pull qwen3.5:9b中国製モデルなので政治的な話題には踏み込まないという制約はあるが、日本語性能は群を抜いていて、業務利用には全く問題ない。
Step 7: N150にDocker + OpenClaw #
OpenClawはセルフホスト型のAIエージェント。Dockerで動かす。
sudo apt update
sudo apt install -y docker.io docker-compose-v2 git
sudo usermod -aG docker $USER
# 再ログイン後
mkdir -p ~/openclaw && cd ~/openclaw
git clone https://github.com/ozbillwang/openclaw-in-docker.git
cd openclaw-in-docker
export OPENCLAW_IMAGE="alpine/openclaw:latest"
docker pull alpine/openclaw:latest
./docker-setup.shセットアップは対話形式で進む。各画面で選んだ内容:
- Setup mode: QuickStart
- Model provider: Ollama
- Ollama mode: Local only(クラウド使わない)
- Default model:
ollama/qwen3.5:9b - Channel: Discord (Bot API)
- Channel access: Allowlist
- Skills: Skip for now(最小構成で開始)
ここまではスムーズだった。
Step 8: Discord Bot連携 #
Discord Developer Portal でBotを作成。
重要ポイント:
- discord.com/developers/applications で「New Application」
- 左メニュー「Bot」→ トークン取得
- 「特権ゲートウェイインテント」3つすべてON:
- PRESENCE INTENT
- SERVER MEMBERS INTENT
- MESSAGE CONTENT INTENT(これ重要)
- 「OAuth2」→ URL Generatorで
botスコープ + 必要な権限を選択 - 生成URLでサーバーに招待
権限は最小限でOK:
- メッセージを送信
- メッセージ履歴を読む
- チャンネルを見る
- 埋め込みリンク
- ファイルを添付
- リアクションの追加
ハマった罠 その1: コンテキストウィンドウ262Kの罠 #
「最強モデルを使いたい」と Qwen 3.6 27B に乗り換えた途端、応答に2時間6分かかった。
原因は、OpenClawのデフォルト設定 contextWindow: 262144(262K)。これがあるとOllamaは262Kトークン分のKVキャッシュバッファを事前確保しようとして、モデル本体の数倍のメモリを食う。
確認すると:
qwen3.6:27b 33 GB 52%/48% CPU/GPU 262144モデル単体で33GBメモリ使用。M4 Pro 24GBに収まらず、SSDへのスワップが発生(9.7GB)。SSDはRAMの10〜100倍遅いので壊滅的に遅くなる。
解決: 設定ファイル ~/.openclaw/openclaw.json の contextWindow を 32768(32K)に変更。
cd ~/.openclaw
sed -i 's/"contextWindow": 262144/"contextWindow": 32768/g' openclaw.jsonこれで:
- Qwen 3.5 9B: 16GB → 9.2GB(本来のサイズに戻った)
- Qwen 3.6 27B: 33GB → 約18GB(ただしまだギリギリ)
教訓: M4 Pro 24GBで快適に動かせるのは9B〜12Bクラスまで。「動く」と「快適に動く」の差は大きい。実用上、32Kコンテキストでも文庫本20ページ分の会話履歴を保持できるので十分。
| メモリ | 動くモデル(快適) |
|---|---|
| 16GB | 7B〜8B |
| 24GB | 9B〜12B |
| 32GB | 20B前後 |
| 48GB | 27B〜32B |
| 64GB+ | 70B〜 |
ハマった罠 その2: Discord channels allowlist の構造 #
セットアップで guildId/channelId 形式で入力したのに、設定ファイルでは guilds: {} (空)で保存されていた。
手動で書き換えようとしてこんな構造にしたら:
"guilds": {
"1504045039519793153": {"allowlist": ["1504045040740208692"]}
}スキーマエラーでクラッシュループに突入。
channels.discord.guilds.1504045039519793153: invalid config: must NOT have additional properties解決: openclaw configure の「Channels」セクションを使って再設定。正しいキーは allowlist ではなく channels だった。
"discord": {
"enabled": true,
"token": "...",
"groupPolicy": "allowlist",
"guilds": {
"xxxxxxxxxxxxxxx": {
"channels": {
"xxxxxxxxxxxxxxx": { ... }
}
}
}
}教訓: OpenClawのスキーマは厳格。手動編集より configure コマンドに任せるのが安全。
ハマった罠 その3 ─ 最大の壁: メッセージが届いてるのに応答が返らない #
Discord連携設定後、Botはオンライン、ログには Discord bot probe resolved @MamioBot と出ている。なのにメッセージを送っても応答が一切返ってこない。
OpenClawのログを見ても受信記録なし。Mac miniのCPUは87% idle、Ollamaに何もリクエストが届いていない様子。
ここで12時間以上消耗した。最終的にClaude Code(コマンドライン版のClaude)に丸投げして解決した。
真の原因 #
visibleReplies: "message_tool" という設定が問題だった。
OpenClawには返信モードが2種類ある:
| 設定値 | 動作 |
|---|---|
"message_tool" |
モデルが message(action=send) という専用ツールを明示的に呼ばないと返信されない |
"automatic" |
モデルが普通にテキストを出力するだけで自動的に送信される |
message_tool モードでは、Qwen 3.5 9Bが返答テキストは生成していたのに、「送信ツールを呼ぶ」という動作を自発的にしなかった。ローカルの9Bモデルはシステムプロンプトで明示的に縛らない限りツール呼び出しを「サボる」傾向がある。結果として、ログ上は処理されているのに payloads=0(Discord側に何も届かない)という状態が続いた。
モデルは答えを作っていたが、「送信」という最後のアクションを取らなかったために届いていなかった。
設定を "automatic" に変更したら、すぐにメッセージが返ってくるようになった。
副次的な改善: thinking モード #
返信が来るようになった後、応答速度が遅かった(2分前後)。Qwen 3.5はデフォルトで「thinking」モード(内部で長考)が有効で、これが冗長な思考プロセスを生成していた。
"params": { "think": false }これを追加したら 2分 → 30秒以内に改善。実用域。
完成後の運用 #
スマホのDiscordアプリから @MamioBot 教えて のように話しかけると、30秒前後で応答が返ってくる。データは外に出ない、完全プライベート。
これから挑戦する人へのアドバイス #
最初の設定で気をつけること:
contextWindowを必ず適切なサイズに(32K程度が日常用途には十分)- Discord の特権ゲートウェイインテント3つ全てON(特にMESSAGE CONTENT INTENT)
visibleReplies: "automatic"を確認(message_toolだと応答が届かない)- thinking モードは用途次第で off にする(チャット用途では速度優先)
TailscaleのACL設定も忘れずに。デフォルトのまま使い始めると全デバイスが相互アクセス可能になる。Tailscale管理コンソールのACLセクションで「誰がどのポートにアクセスできるか」を絞っておくとより安全だ。
デバッグで見るべきログ:
docker compose logs -f openclaw-gatewaypayloads=0 が出ていたら message_tool モードを疑う。
詰まったらClaude Codeに投げる。設定ファイル全体・ログ全体を横断的に読んでくれるので、チャット版のAIで延々と切り分けるより圧倒的に早い。
まとめ #
完成までの所要時間は丸2日。ほとんどは罠との戦いだった。それでも、自宅サーバーで完全プライベートに動くAIアシスタント環境が手に入ったのは大きな価値がある。
クラウドAIに依存しない、データを外に出さない、好きなモデルを試せる。これがローカルLLM運用の魅力。
次はNotionやKeepに溜まった膨大なメモをRAG(検索拡張生成)で統合し、完全プライベートな「セカンドブレイン」を構築していく予定。それも記事にする。
今回の構築で使った主な技術
- Tailscale(VPN)
- Docker(コンテナ)
- Ollama(LLM実行環境)
- Qwen 3.5 9B(LLMモデル)
- OpenClaw(AIエージェントフレームワーク)
- Discord(操作インターフェース)

